
Was passiert, wenn Sie einige der klügsten IT-Köpfe in Ihrem Unternehmen auf Innovation statt auf den Betrieb ausrichten?
Das ist eine Frage, die wir unseren Kunden oft stellen. Kürzlich haben wir uns selbst gefragt. Die Antwort - dieses Mal - ist ein Produkt, das völlig anders ist, und doch ganz im Einklang mit dem Fokus von bat365steht, Unternehmen zu befähigen, erstaunliche Dinge mit unstrukturierten Daten zu tun.
Cloud Block Store ist ein Ableger der blitzschnellen Technologie von bat365 Data Services , mit der Milliarden von Dateien von bat365 und anderen Dateifreigaben in nahezu Echtzeit aufgenommen, durchsucht, analysiert, geprüft und überwacht werden können. Es handelt sich um eine hyperkonvergente Cloud-native Speicherplattform, die nach Bedarf bereitgestellt und skaliert werden kann.
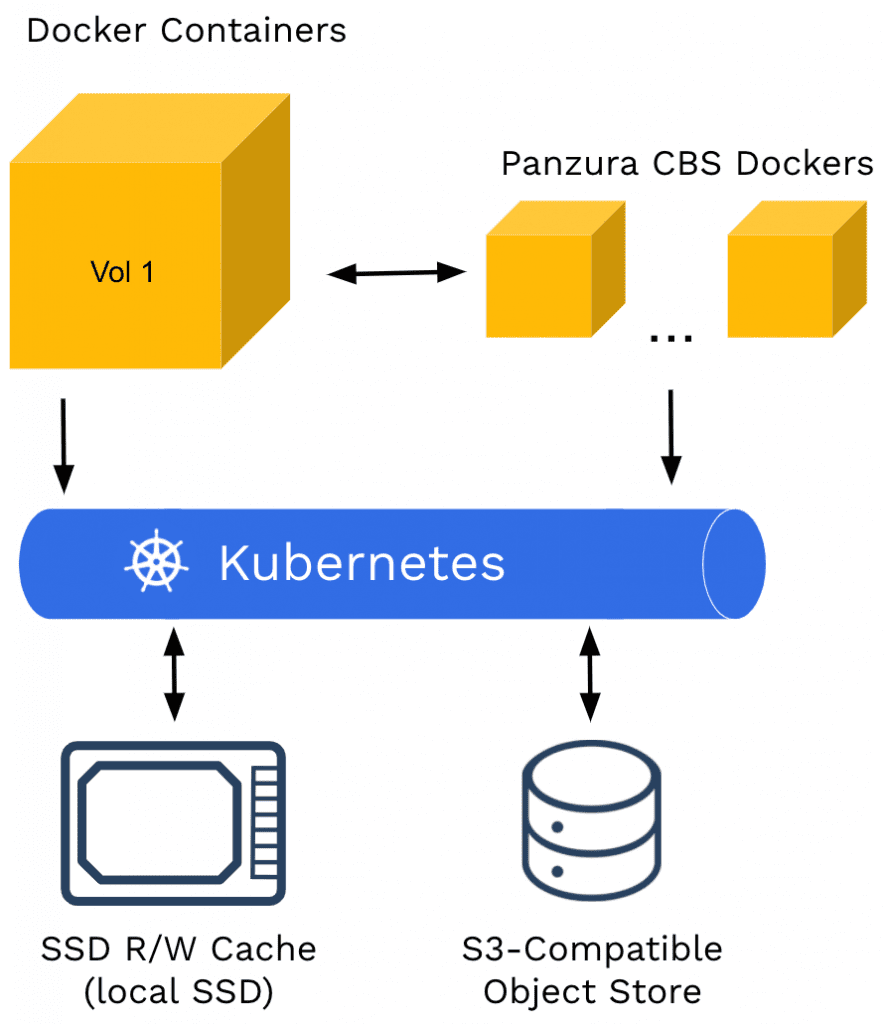
Der im Google Cloud Platform (GCP) Marketplace für Google Kubernetes Engine (GKE) Cluster verfügbare bat365 Cloud Block Store (CBS) ist eine webbasierte, persistente Kubernetes-Speicherplattform für containerisierte Anwendungen. Der Cloud Block Store kann nach oben skaliert werden, wenn Sie mehr Ressourcen benötigen, oder nach unten, wenn weniger Ressourcen benötigt werden. Ohne Skalierungsgrenzen bietet CBS einen skalierbaren, verteilten Lese-Cache für containerisierte Anwendungen und optimiert Kubernetes-Cluster-Ressourcen für Hochleistungs-Workloads.
Warum ist Cloud Block Store wichtig für Kubernetes?
Container werden heute in Organisationen von kleinen Startups bis hin zu großen Unternehmen eingesetzt. Organisationen benötigen verschiedene Ebenen der Datenpersistenz für ihre containerisierten Anwendungen. Kubernetes-Anwendungen wurden für die Verwendung von Volumes entwickelt, die dem Container auf Pod-Ebene folgen, d. h. sie werden zusammen mit den Pods erstellt und gelöscht. Diese Anwendungen werden als zustandslos bezeichnet. Viele Containeranwendungen benötigen einen Volumenspeicher, der Informationen während der Nutzung des Containers speichert, um verfügbar zu sein, wenn der Container oder Pod gelöscht wird. Beim Neustart des Pods oder Containers müssen alle Datenänderungen, die aufgetreten sind, aufgelöst werden.
Mit anderen Worten: Die Datenträger verhalten sich eher wie eine Datenbank. Diese Anwendungen werden als zustandsorientiert bezeichnet.
bat365 Cloud Block Store bietet die persistenten Speichervolumina, die sowohl für zustandsbehaftete als auch für zustandslose Anwendungen erforderlich sind, indem ein skalierbarer verteilter Lese-Cache erstellt wird. Dieser Lese-Cache ist ein Cluster aus skalierbaren GKE-Knoten, der für eine hohe Datenverfügbarkeit sorgt und sich leicht in Kubernetes-Anwendungen integrieren lässt.
Die Optimierung von Cloud Block Store konzentriert sich auf Leistung und Zuverlässigkeit. Um das Einlesen von Blöcken zu beschleunigen und sie im Falle eines Knotenausfalls vor Verlust zu schützen, setzt Cloud Block Store gemeinsam genutzte, mehrfach redundante Cache-Dienste für den einfachen Zugriff auf Daten ein. Dadurch wird eine optimale Leistung erreicht, denn wenn ein Lese-Cache-Knoten ausfällt, kann ein anderer Knoten auf die Daten aus den Cache-Diensten zugreifen. Alle Daten werden schließlich in Google Cloud Storage gespeichert, um eine langfristige Haltbarkeit zu gewährleisten.
Der Cloud Block Store ist als eine Sammlung von Pods und Containern implementiert, die von Kubernetes verwaltet werden. Kubernetes setzt die optimale Anzahl jedes Containertyps ein, um das gewünschte Serviceniveau aufrechtzuerhalten.
Die automatische Skalierung für mehr Ressourcen erfolgt, wenn Lese-Cache-Treffer einen Schwellenwert von Hit-Misses überschreiten. Die Skalierung erfolgt, wenn ein Cache-Trefferschwellenwert eine untere Hit-Miss-Grenze oder eine Bandbreitenrate von 1 MB/Sek. oder weniger überschreitet, was bedeutet, dass weniger Ressourcen verwendet werden.
Die Verkleinerung senkt die Kosten für die Nutzung der Cloud Block Store-Kapazität, da Kunden nur 0,0003 US-Dollar pro Gigabyte/Tag Google Cloud Storage zahlen. Zusätzliche Kosten für den Google Kubernetes Engine-Cluster fallen an und sind von CBS getrennt. Nachfolgend finden Sie einige wichtige Informationen zu den Funktionen und der Architektur von CBS.
Merkmale:
- Thin Provisioned, globale Deduplizierung und Komprimierung
- AES256 Verschlüsselung
- CSI-Treiber-Beschwerde
- Unbegrenzt mountbare Snapshots
- Einfach zu implementieren über CLI und Automation
- Echtzeit-Statistiken und Berichte
- Unterstützung für Intel Optane im AppDirect-Modus (16TB Cache)
- Leistungsstarke POSIX-Volume-Schnittstelle
Web-basierte Architektur:
- Bis zu 1PB Volume Namespace
- 100 TB oder mehr verteilter Lese-Cache auf lokaler und persistenter SSD
- Automatisches Verkleinern und Verringern, basierend auf Lese-Cache-Treffern (und Kosten)
- Sicherung, Archivierung und Analyse-Workloads Optimierte E/A-Leistung
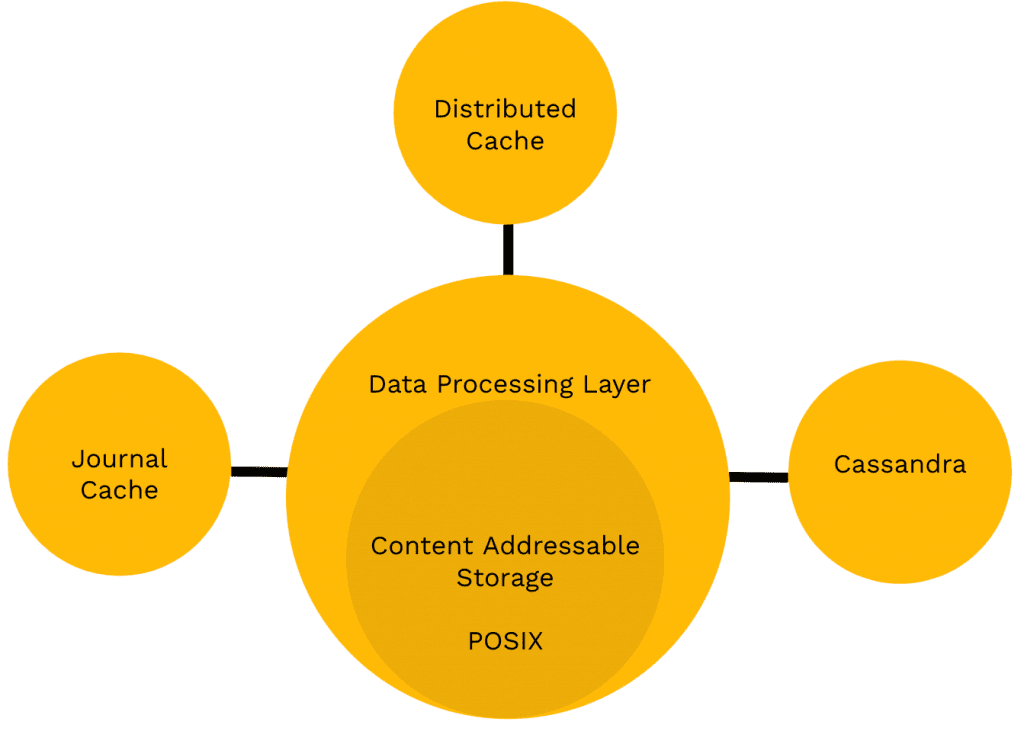
Die Datenverarbeitungsschicht (Data Processing Layer, DPL) akzeptiert/verarbeitet Client-Anforderungen von einem Blockgerät oder einem S3-Dienst. Globale Deduplizierung, Komprimierung und Konvertierung in eine 4K-Blockgröße werden im DPL durchgeführt und sorgen für eine effiziente Datenspeicherung für performante Datenoperationen.
Der Cloud Block Store wird als verteilter Lese-Cache für Client-Anwendungen als hochleistungsfähige POSIX-Schnittstelle präsentiert. Der Journal-Cache-Dienst garantiert, dass Daten, die sich nicht im verteilten Lese-Cache befinden, im Journal-Cache verfügbar sind, und Metadaten in anderen Cache-Diensten befinden sich im Cassandra-Backend-Dienst. Alle Cache-Dienste arbeiten zusammen, um Daten von jedem Knoten im GKE-Cluster für Client-Anfragen verfügbar zu halten.
Wichtigste Highlights
- Cloud Block Store ist ein skalierbarer blockbasierter Cache, der von allen Recheninstanzen innerhalb eines GKE-Clusters gemeinsam genutzt wird.
- Kubernetes-Anwendungen, die eine Block-Device-Schnittstelle verwenden, können vom Cloud Block Store profitieren.
- Der Cloud Block Store wird Kubernetes-Anwendungen als persistenter Datenträger präsentiert, der eine leistungsstarke POSIX-Schnittstelle als ein einhängbares Verzeichnis für einen Container oder Pod nutzt.
- Der Distributed Read Cache Service ist skalierbar, so dass weitere Knoten mit zusätzlichen lokalen persistenten SSDs hinzugefügt werden können, um die Kapazität zu erhöhen.
- Alle in den Cloud Block Store aufgenommenen Blöcke werden schließlich zur dauerhaften Speicherung in die S3-Backend-Cloud hochgeladen.
- Nur die Daten, auf die zuletzt und häufig zugegriffen wurde, werden im Cloud Block Store als verteilter Lese-Cache gespeichert (lokale SSD der Knoten).
- Wenn ein Block von einem Benutzer angefordert wird, kann jeder Knoten im verteilten Cache-Knoten antworten, unabhängig davon, welcher Knoten diesen Block im Cache speichert. Dies ist auf die globale Deduplizierung beim Einlesen zurückzuführen. Jeder Block kann zu jeder Zeit gelesen werden.
- Wenn ein Block nicht zwischengespeichert wird, wird er aus S3 (GCP-Speicher) abgerufen und wieder im verteilten Lese-Cache gespeichert.
Zusammenfassend lässt sich sagen, dass bat365 Cloud Block Store eine Vorreiterrolle bei der persistenten Containerspeicherung für Cloud-native Architekturen für containerisierte Unternehmensanwendungen einnimmt. Durch die Verwendung einer Vielzahl neuartiger Ansätze, um die Kosten niedrig zu halten, bietet Cloud Block Store einen klaren ROI, indem es Ihnen ermöglicht, hochleistungsfähigen persistenten Kubernetes-Container-Speicher zu nutzen. Die Installation erfolgt einfach über den Google Cloud Platform Marketplace. Ein Google Kubernetes-Engine-Cluster ist Voraussetzung. Die auf der Marketplace-Website verfügbare Dokumentation enthält empfohlene Cluster-Spezifikationen, gcloud-Beispielbefehle für die Installation und eine CBS-Verwaltungsschnittstelle zur Ausführung von API-Aufrufen für wertvolle Einblicke in Cloud Block Store.